High Availability Architecture Patterns | FileCloud
December 15, 2015
High Availability Architecture Patterns in FileCloud As the number of mission-critical web-based services being deployed by enterprise customers continues to increase, the need for a deeper understanding of designing the optimal network availability solutions has never been more critical. High Availability (HA) has become a critical aspect in the development of such systems. High Availability […]
High Availability Architecture Patterns in FileCloud
As the number of mission-critical web-based services being deployed by enterprise customers continues to increase, the need for a deeper understanding of designing the optimal network availability solutions has never been more critical. High Availability (HA) has become a critical aspect in the development of such systems. High Availability simply refers to a component or system that continuously remains operational for a desirable amount of time. Availability is generally measured relative to ‘100 percent operations’; however, since it is nearly impossible to guarantee 100 percent availability, goals are usually expressed in the number of nines. The most coveted availability goal is the ‘five nines’, which translates to 99.999 percent availability – the equivalent of less than a second of downtime per day.
Five nines availability can be achieved using standard commercial quality software and hardware. The design of high availability architectures is largely based on the combination of redundant hardware components and software to manage fault correction and detection without human intervention. The patterns below address the design and architectural consideration to make when designing a highly available system.
Server Redundancy
The key to coming up with a solid design for a highly available system lies in identifying and addressing single points of failure. A single point of failure simply refers to any part whose failure will result into a complete system shutdown. Production servers are complex systems whose availability is dependent on multiple factors, including hardware, software and communication links; each of these factors is a potential point of failure. Introducing redundancy is the surest way to address single points of failure. It is accomplished by replicating a single part of a system that is crucial to its function. Replication guarantees that there will always be a secondary component available to take over in the event a critical component fails. Redundancy relies on the assumption that they system cannot simultaneously experience multiple faults.
The most widely known example of redundancy is RAID-Redundant Arrays of Inexpensive Disks, which utilizes the combined use of multiple drives. Server redundancy can be achieved through a stand-by form also referred to as active-passive redundancy or through active-active redundancy where all replicas are concurrently active.
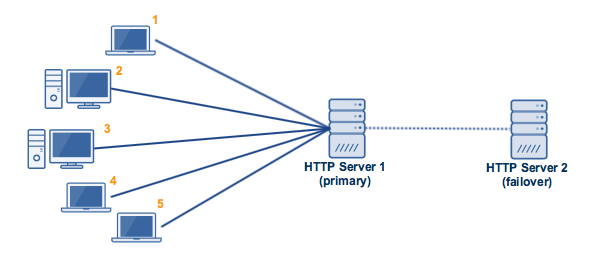
Active-Passive Redundancy
An active-passive architectural pattern consists of at least two nodes. The passive server (failover) acts as a backup that remains on standby and takes over in the event the active server gets disconnected for whatever reason. The primary active server hosts production, test and development applications.
The secondary passive server essentially remains dormant during normal operation. A major disadvantage of this model is that there is no guarantee that the production application will function as expected on the passive server. The model is also considered a relatively wasteful approach because expensive hardware is left unused.
fig 1.1
Active-Active Redundancy
The active-active model also contains at least two nodes; however, in this architectural pattern, multiple nodes are actively running the same services simultaneously. In order to fully utilize all the active nodes, an active-active cluster uses load balancing to distribute workloads across the nodes in order to prevent any single node from being overloaded. The distributed workload subsequently leads to a marked improvement in response times and throughput.
The load balancers uses a set of complex algorithms to assign clients to the nodes, the connections are typically based on performance metrics and health checks. In order to guarantee seamless operability, all the nodes in the cluster must be configured for redundancy. A potential drawback for an active-active redundancy is that in case one of the nodes fails, client sessions might be dropped, forcing them to re-login into the system. However, this can easily be mitigated by ensuring that the individual configuration settings of each node are virtually identical.
fig 1.2
N+1 redundancy
An N+1 redundancy pattern is sort of a hybrid solution between active-active and active-passive; it is sometimes referred to as parallel redundancy. Despite the fact that this model is mostly used as UPS configuration, it can also be applied for high availability. An N+1 architectural pattern basically introduces 1 slave (passive) for N potential single point of failures in a system. The slave remains in standby mode and waits for a failure to occur in any of the N active parts. The system is therefore granted the capability of handling failure in one out of N components with compromising performance.
fig 2.1
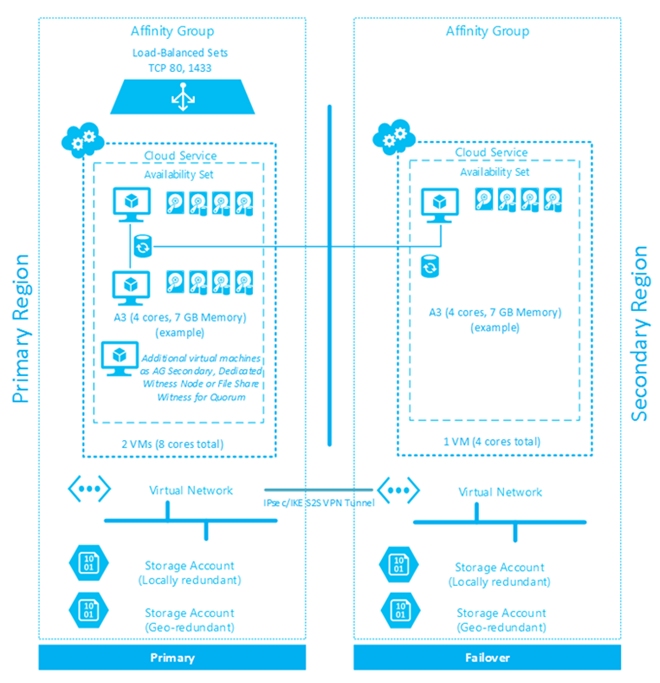
Data Center Redundancy
While a datacenter may contain redundant components, an organization may also benefit from having multiple datacenters. Factors such as weather, power failure or even simple equipment failure may cause an entire datacenter to shut down. In this scenario, replication within the datacenter will be of very little use. Such an unplanned outage can be a significantly costly affair for an enterprise. When failures on a data center level are considered, the need for a high availability pattern that includes multiple servers becomes apparent.
It is important to note that establishing multiple data centers in geographically distinct locations, and buying physical hardware to provide redundancy within the datacenters, is extremely costly. Additionally, setting up is a time-consuming affair, and may seem too difficult to achieve in the long-run. However, high purchase, set-up and maintenance costs can be mitigated by employing the use of IaaS (Infrastructure as a Service) providers.
fig 3.1
Floating IP Address
A floating IP address can be worked into a high availability cluster that uses redundancy. The term ‘floating’ is used because the IP address can be moved from a one droplet to another droplet within the same cluster in an instance. This means the infrastructure can achieve high availability by immediately pointing an IP address to a redundant server. Floating IPs significantly reduce downtime by allowing customers to associate an IP address with a different droplet. A design pattern that has provisions for floating IPs makes it possible to establish a standby Droplet, which can receive production traffic at moment’s notice.